![小蝠猫学算法#4——[线性表表示]](https://pic2.imge.cc/2024/09/22/66efb2e940df0.png)
小蝠猫学算法#4——[线性表表示]
文章寄语
命运负责洗牌和发牌,而我们只能出牌。
—— 叔本华<<人生的智慧>>
引言
数据结构笔记第四篇。线性表的顺序表示[考纲有此内容]
知识点大致按照《Hello!算法》书籍进行。因为数据结构与算法在非常多的考试中都有。
本人基础较弱,可能会有许多错误,恳请批评指正。
下面是几个上述提到的链接:
《Hello!算法》网页版 全国计二级官网 洛谷官网-刷题可用星空如此灿烂,灯塔与之响应。出发吧
第四节 线性表的顺序表示
线性表定义
线性表是具有相同数据类型的有限序列。特点如下:
- 表长为0时,表中没有元素,为空表.
- 第一个元素称为表头元素,最后一个元素称为表尾元素。
- 简单来讲,直接后驱即除了表尾,每个元素的后面有且仅有一个元素;直接前驱即除了表头,每个元素的前面有且仅有一个元素。即具有逻辑上的顺序性。
- 因为相同数据类型,每个元素占用的空间相同。
- 仅讨论逻辑性,即每个元素的位置和逻辑关系等。不会去关心这些元素到底是什么。
线性表的基本操作
主要操作:
InitList(&L);初始化表,构造一个名为L的空线性表。涉及实际修改,可加引用。Length(L);统计表L中元素的个数。LocateElem(L, e);定位元素,在L中按值查找值为e的元素。GetElem(L, i);获取元素,在L中按位获取第i位的元素。ListInsert(&L, i, e);插入元素,在L中的第i位前插入元素e。涉及实际修改,可加引用。ListDelete(&L, i, &e);删除元素,删除L中的第i位元素,并返回被删除的e的值。涉及实际修改,可加引用。PrintList(L);遍历输出L的所有元素。Empty(L);判断L是否是空表。DestroyList(&L);销毁线性表,释放内存。涉及实际修改,可加引用。
1 | void swap(int &x, int &y) { |
在以上例子中,主要的功能是交换两个数字的值。有时候可能会写 int swap(int x, int y)。
但是这种情况下写到最后会发现,咦,函数一般不是都是返回一个值吗?如果返回两个值,那我该怎么办?
引用号’&’的意义
后来我发现,c++里面有一个 &符号可以使用。这是一种元素别名,他可以直接控制原变量的值。
如果在主函数内定义好了a和b的值后使用 swap(a, b)传入,并在 void swap(int &x, int &y)内开始处理后,
因为 &引用号需要一个东西来绑定。上述代码使用了 &后,x即和a绑定,y即和b绑定。
现在在函数内部 void swap(int &x, int &y)中对x,y的修改,便会同步到外部的a,b上。对引用的操作等同于对原始变量的操作。
问题就解决了。函数内的x,y可以直接对主函数的a,b进行改写。不需要考虑返回多个值的苦恼了。
引用号’&’的使用场景
x,y是变量需要声明,且声明时就应该直接和变量绑定并初始化,不能改绑。且若将引用作为函数参数时。函数内直接用就行不需要重复定义。
若涉及到对主函数变量的修改,就可以添加引用号。如果没有实际操作可以不用,引用不占用额外内存空间。
引用号’&’和指针号’*’的对比
指针的本质是一种数据类型,用于存储内存地址。因为数据访问都会通过内存地址,相当于直接操纵底层,所以使用指针得特别小心。
如果造成空指针,野指针事件,很可能造成所有数据的损坏,或者指向了一个不存在的地址,而导致崩溃报错。
但是引用就不一样了,它只是一种元素别名,不操控内存,对引用的操作只操控原始元素。其他不是他要管的,所以比较安全。
顺序表定义
线性表—顺序表
顺序存储即顺序表,将相同类型的元素按顺序放置在一个连续的内存中。元素在顺序表中的位次和在内存中的相同。位次称作为元素在这个表中的”索引”,即逻辑顺序与其存储的物理顺序相同。
因为相同元素类型,分配给每个元素的内存大小都是相同的。可以通过索引和首地址轻松的算出任何元素的内存地址。
假设索引从0开始,首元素地址为00,每个元素分到4字节:
- 第0个元素内存地址为:00
- 第1个元素内存地址为:00 + 4 * 1
- 第n-1个元素内存地址为:00 + 4 * (n - 1)
所以可以任意算出任何内存地址:首元素地址 + 元素大小 * 当前元素索引。这个性质也叫做”随机存取”。
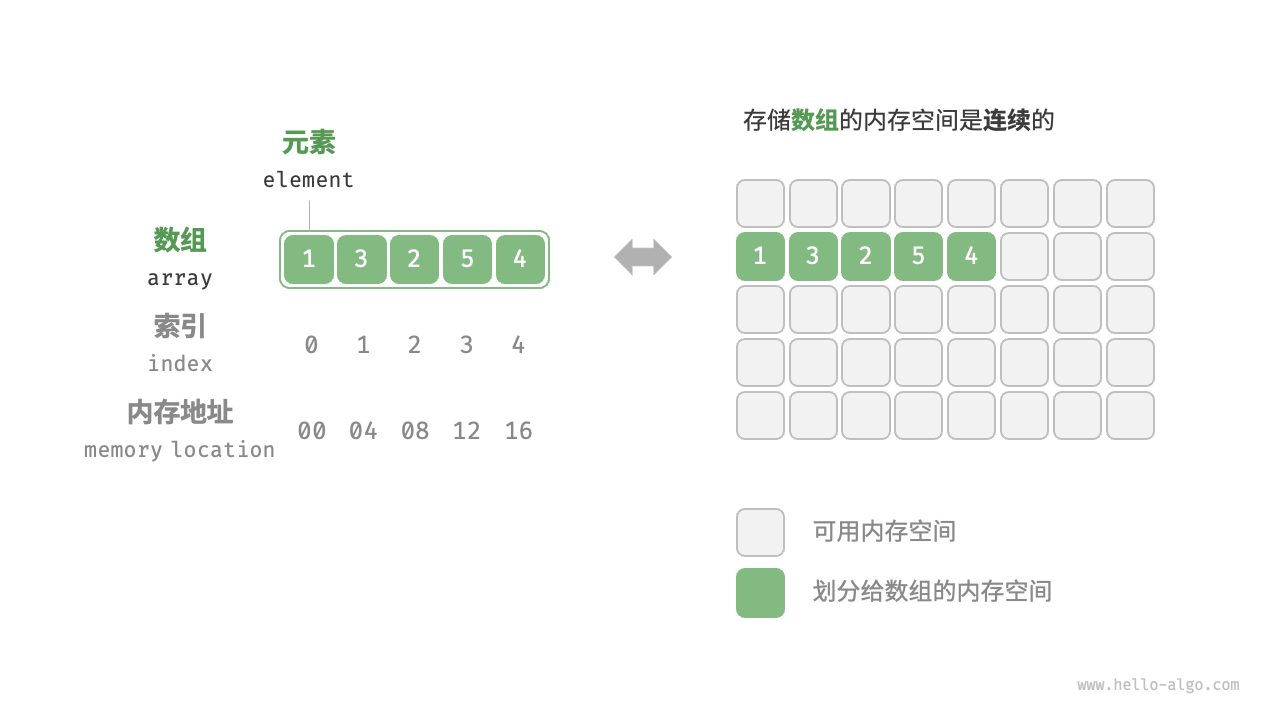
线性表—数组
数组是顺序存储的一种常见形式。他可以静态分配内存,也可以动态分配内存。
索引和位序是不一样的。位序从1开始,类似于座位。索引从0开始,我也举不出例子。
静态分配内存
静态分配即提前约定顺序表长度。因为同类型元素,每个元素所占的内存空间均相同的。所以总空间即元素个数 * 元素大小。
如果访问时超过这个大小,就会出现”数组越界” (ArrayIndexOutOfBoundsException)报错。 解决办法也很简单,要不扩大数组,要不删除元素。
C语言中,字符串数组的末尾会包含结束符\0。意味着如果长度为是5位,因为包含\0,他读到第4位就会停止,可能会忽略第5位。
动态分配内存
动态分配会提前申请一大块内存,将这些元素存入。当顺序表占满后,如果还有元素存入,他会重新申请更大的内存。当这块内存使用完毕时,使用free()函数释放内存。
如果忘记使用free()函数,可能会导致内存泄露,占用巨量内存。除了malloc()函数,还可以使用calloc()函数动态分配内存。
- malloc()需要1个参数,告诉申请开辟多少内存空间,单位是字节。空间值可能随机。
- calloc()需要2个参数,需要分开告诉申请个数和元素大小。同时会把空间值全部初始化为0。
c的动态分配: 使用malloc函数开辟。ElemType指当前元素数据类型,sizeof指获取当前元素大小,initsize指初始表长。即malloc了一个元素大小*个数的内存空间。
1 | L.data = (ElemType*)malloc(sizeof(ElmeType) * InitSize); |
c++的动态分配: 使用new函数开辟。ElemType指当前元素数据类型,initsize指初始表长。即new了一个ElemType类型初始个数为initsize的内存空间。
1 | L.data = new ElmeType[InitSize]; |
还可以使用vector等来动态管理顺序表。通过insert插入元素,自动管理新增元素和内存分配。
顺序表的基本操作
Ⅰ.初始化元素
当未指定初始值初始化时,若该变量使用四则运算时会出现问题,最好还是指定初始值。变量会被另外的值覆盖时,可以不给初始值。
Ⅱ.访问元素
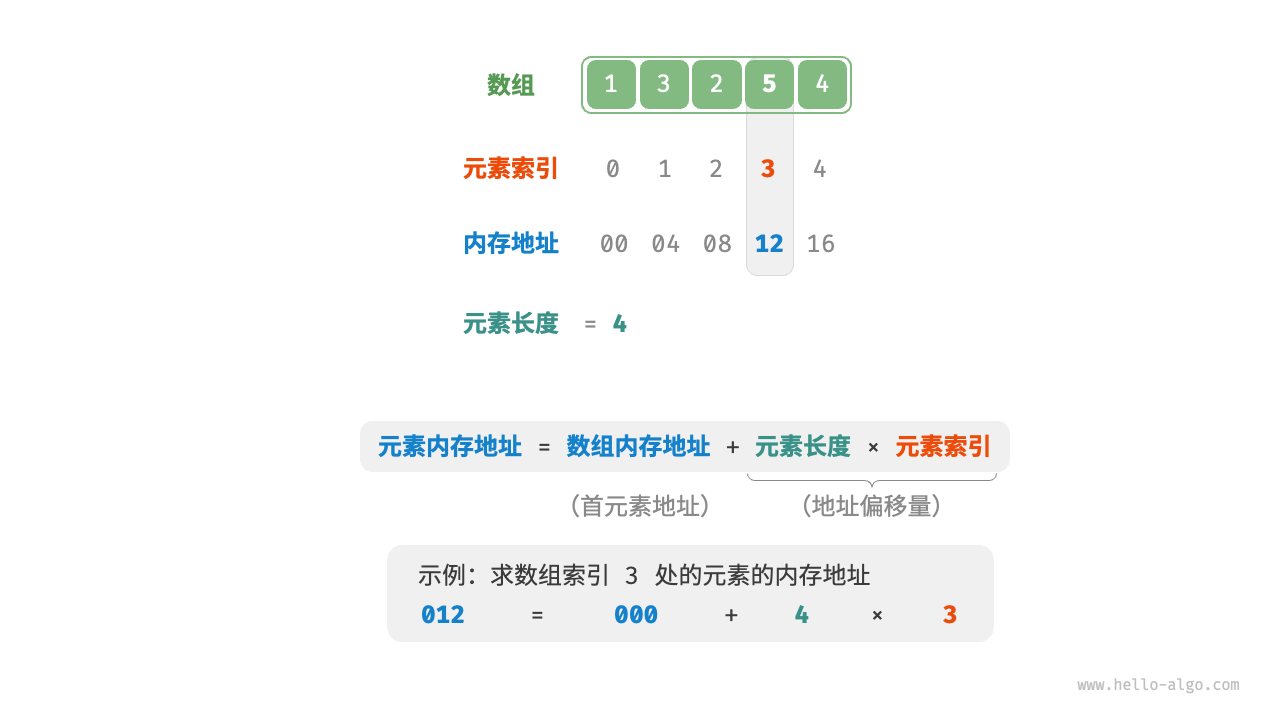
因为”随机存取”,计算任意元素的内存地址非常容易。且从地址计算的角度看,索引*长度本质上是内存地址的偏移量,正是通过这个偏移量,才能求出其他位置的元素地址。
顺序表中访问元素的时间复杂度为常数级。
Ⅲ.遍历元素
可以用索引下标遍历,也可以用for等语句直接遍历。
Ⅳ.插入元素
因为元素在顺序表中和在内存中均是”连续存储”。当有人插队,此位置之后的所有人均要往后退一步,腾出位置才能让其插入。
如果插入时顺序表已满,就会插入失败,可能导致尾部元素丢失。
1 | //对数组L的第i位插入数据类型为ElemType的元素e |
如果把 L.data[j] = L.data[j - 1];代码换成 L.data[j + 1] = L.data[j];,虽然看起来功能相同,但是在数组L中,第length+1位是不存在的,会导致报错。
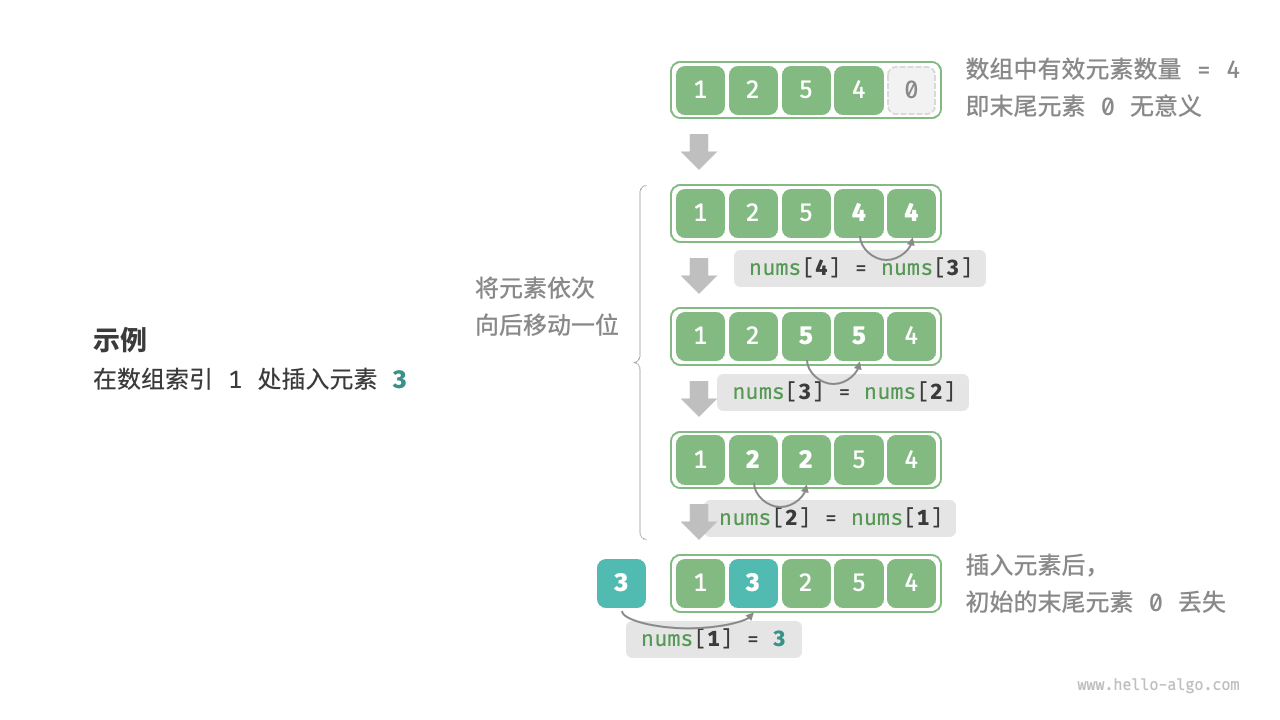
对于这段代码,最坏的情况下是在头部插入,那么所有元素都要往后移一位。因此顺序表插入元素算法的时间复杂度是线性阶
Ⅵ.移除元素
和添加元素的代码大体相同,只不过是元素前移。但是if语句中现在是length,因为不会出现越界的问题了。删除元素时,将后项值赋给前项,完成元素前移。即 L.data[j - 1] = L.data[j]。
完成操作后,可能在尾部会多出来一个没用的值。这个值没有意义,也不用特意去操作。
最坏的情况下是在头部删除,后面的值全部要前移。所以顺序表删除元素算法的时间复杂度是线性阶
Ⅶ.查找元素
按值查找,因为最坏情况需要全遍历一遍才能找到,所以是线性阶。按序查找,因为随机读取的特性,所以是常数阶。
Ⅷ.扩容元素
扩容元素一般是重新申请更大的内存块,而不是扩容,扩容未知可能把内存撑爆。通过重新建立一个更大的数组,把原来的元素全部复制过去来完成。
因为要全部遍历一遍,所以是线性阶。在数组个数过于庞大时,重新申请会浪费较多的资源,这时候只能找别的办法。
顺序表的优缺点
优点密度高,支持随机访问,还有一个书上的*缓存局部性(数组加载时还会加载周围的数据)*。
缺点增删查都是线性阶
总结
文章结语
我们现在所做的,只不过是我们自认为动态规划中的贪心罢了。
——博客园某用户
笔记完毕 编辑完毕时间CST 7.18 22:55
最后编辑时间8.15 23:40
- 本文标题: 小蝠猫学算法#4——[线性表表示]
- 本文作者: 蝙蝠猫BatBattery
- 定文于 : 2024-07-17 20:55:00
- 翻新于 : 2024-10-05 15:14:39
- 本文链接: https://smallbat.cn/hellonotes/hellonotes-4/
- 版权声明: 懒得写版权,本篇只是学习笔记.转载,引用随意,添加来源即可.